Insights
Stephen Poletto
The Unmeasured Half of the Model x Harness Equation
Anthropic published a piece in May on how Claude Code works in large codebases, and buried in the middle is an admission worth dwelling on. In their words: one of the most common misconceptions about Claude Code is that its capabilities are solely defined by the model. In practice, "the ecosystem built around the model—the harness—determines how Claude Code performs more than the model alone."
While capability differences between models are real, the model by itself isn’t what generates great results. The company whose entire valuation rests on frontier model capability is telling you that real-world performance is differentiated by the harness - e.g. the scaffolding of context files, hooks, skills, and tooling wrapped around the model. Yet the majority of industry attention has gone toward benchmarking the model.
The half of the system we as software operators actually own and operate is the harness. And that half, right now, is in a strikingly primitive state. There's little engineering discipline around it: minimal established patterns, no measurement conventions, barely any tooling. It's folklore, blog posts, and hand-edited text files.
One factor in the equation compounds on a frontier lab's R&D budget, and a myriad of benchmarking methodologies; the other depends on… markdown file curation, and judgment?
The State of the Art is... Markdown Files
Strip away the terminology - CLAUDE.md, skills, progressive disclosure, plugins - and here's what the leading practice amounts to(*): humans distill key learnings and constraints about a codebase into markdown files, then arrange those files so they're disclosed to the agent progressively, based on the task at hand.
The logic is sound. If the agent is changing the billing service, you don't want it ingesting documentation about the notifications pipeline. Irrelevant context isn't neutral; it actively degrades performance and burns context windows. So you scope context to the work: a root file with the big picture, subdirectory files with local conventions, skills that load on demand when the task calls for them. Anthropic's own guidance is explicit that too much context loaded into every session degrades performance, while too little leaves the agent navigating blind.
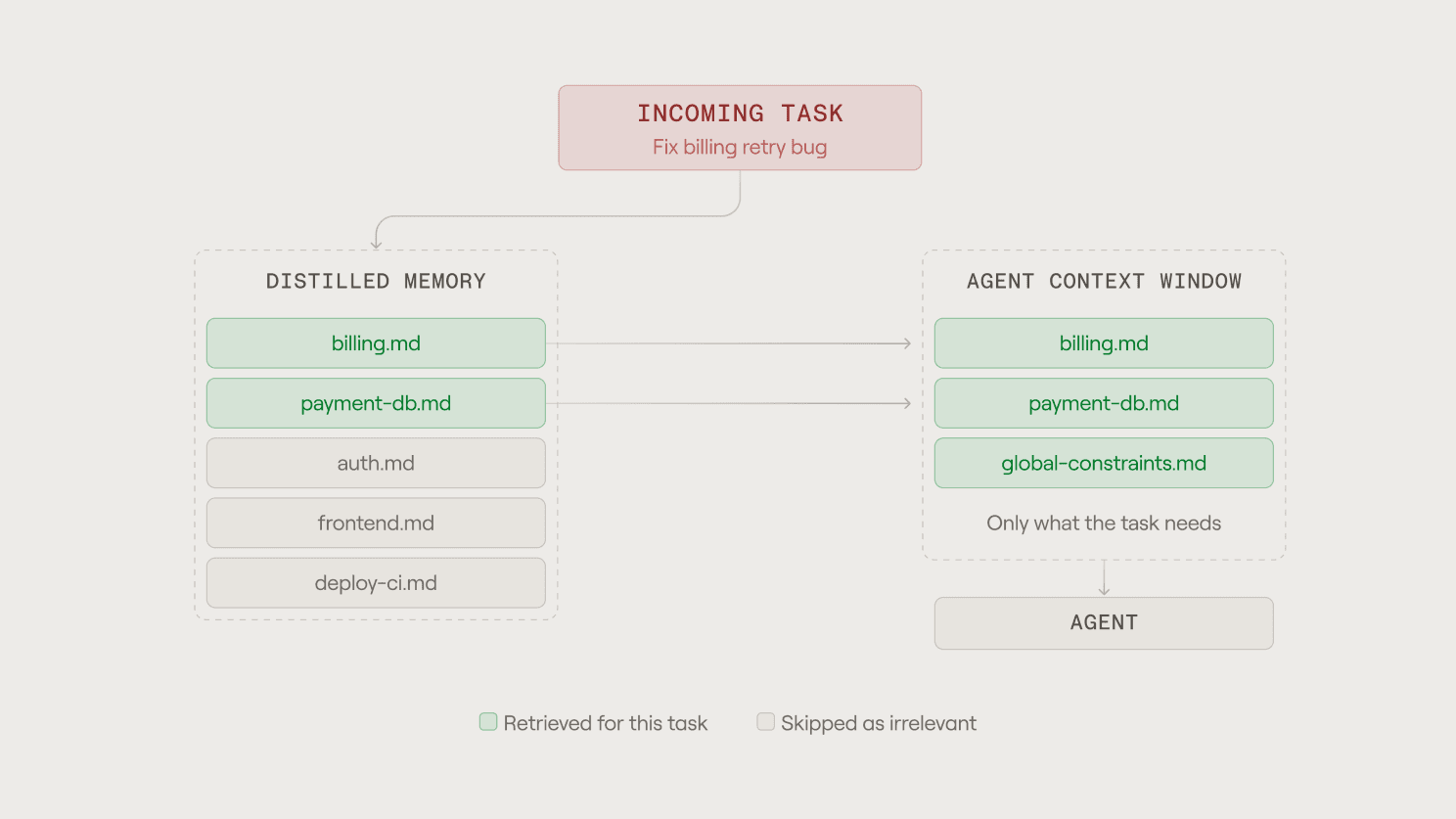
What we've built, in effect, is a smart index of relevant artifacts that get retrieved, curated, and fed into the agent. The operating principle behind all of it is simple: the higher the relevancy of the provided context, the higher the accuracy of task completion.
That principle is correct. But step back and look at the implementation. We are hand-authoring text files, hand-deciding what goes where in a directory hierarchy, and hand-pruning them every few months as models evolve. Anthropic literally recommends a configuration review every three to six months because instructions written for today's model can actively constrain tomorrow's. This is artisanal. It's the agentic equivalent of hand-tuning database indexes before query planners existed.
Rudimentary, But it's What We've Got
I want to be fair: rudimentary doesn't mean wrong. This is the best approach available today, and teams that invest in it see meaningfully better results than teams that don't. The agentic memory problem - e.g. what should the agent know, when should it know it, and how does that knowledge stay current - is genuinely hard, and curated markdown is a perfectly reasonable v1.
Notice, too, what that three-to-six-month pruning cycle is telling you: the two factors are coupled. Instructions tuned for one model can actively constrain its successor. Neither side of the multiplication holds still, which means harness work is never "done.” It co-evolves with the model you’re using underneath it.
But precisely because it's a v1 built on human judgment and folklore, we should be rigorous about one thing: knowing whether the changes we make to it actually improve outcomes, and knowing how it performs with Model A vs. Model B.
If You Can't Measure it, You're Guessing
Here's the test for whether your team is doing rigorous harness engineering or harness theater: can you answer these two questions?
What is our task success rate? Of the tasks we hand to coding agents, what fraction complete acceptably: pass review, make it through CI/CD, no human rewrite, no defects or incidents in production?
What is our spend per success? Not spend per token or spend per session. Spend per successfully completed task, including the retries and the failures.
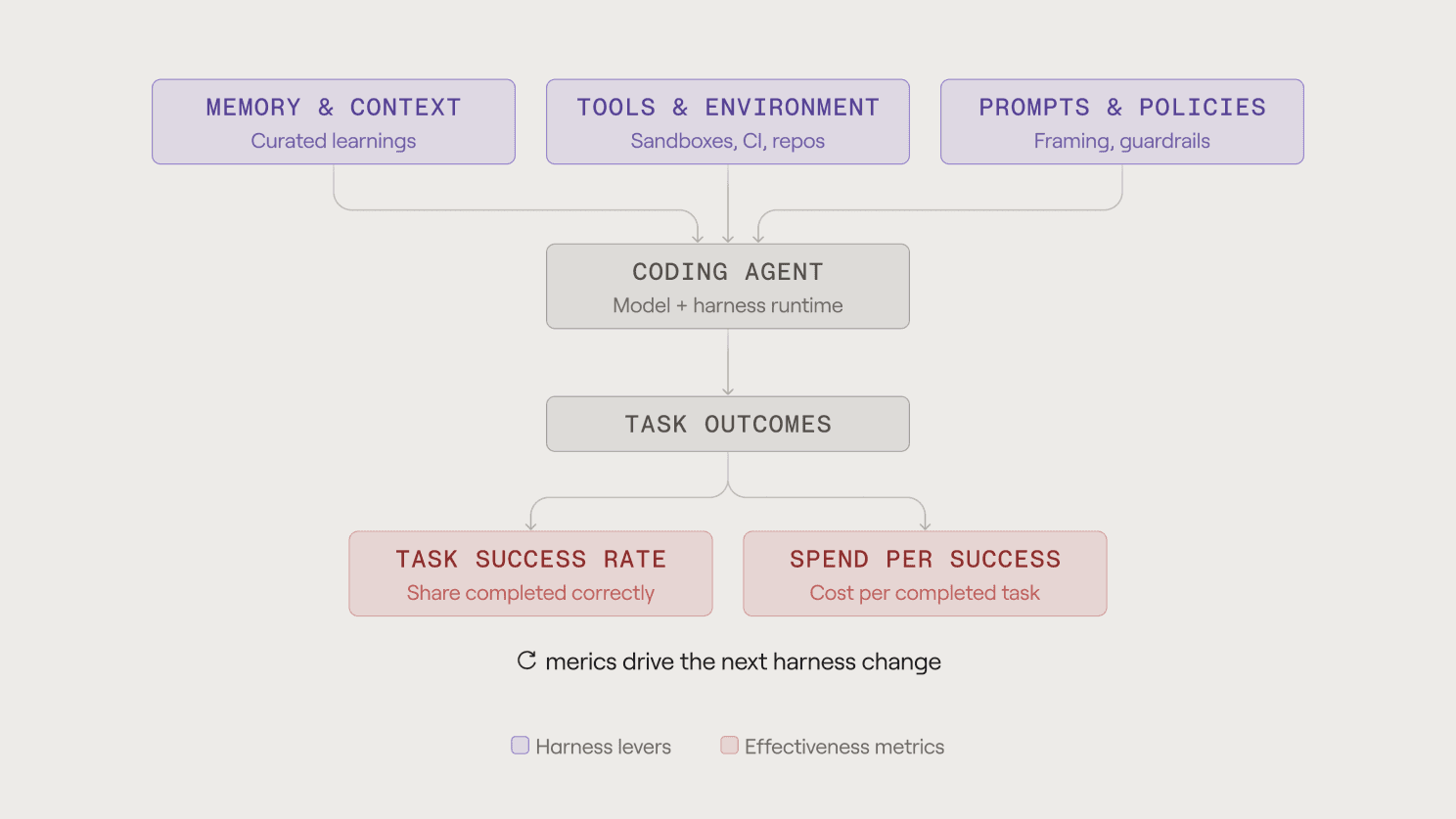
If you can't answer those, you have no way of knowing whether the CLAUDE.md refactor you did last sprint helped, hurt, or did nothing. You're making changes to a system whose output you don't observe. Most teams are in exactly this position. They've adopted the tools, they've accumulated the markdown, and they're operating on vibes.
This isn't a moral failing: the tooling for agent evaluation is immature, and instrumenting "success" is harder than instrumenting latency. But it's the single highest-leverage thing a platform team can invest in right now, because it increasingly guides their development effort toward measurable improvement.
The Cost Conversation is Really a Confidence Conversation
There's been a lot of hand-wringing about the cost of these systems growing to unreasonable levels, and the hand-wringing isn't wrong: agentic workflows on frontier models are expensive (especially when agents run in retry loops and waste tokens), and the bills are getting attention from people who sign them.
Smaller, cheaper models exist. The reason teams don't route work to them is not that the models are categorically incapable. It's that we lack confidence in getting deterministic, acceptable outputs from them. We pay the frontier premium as insurance against variance.
Memory is the Lock-in Nobody's Built Yet
Models today are differentiated but not sticky. The capability deltas are real, which is why the frontier premium exists at all. But the switching costs are low. The interfaces are converging, the harnesses are increasingly model-agnostic, and swapping one frontier model for another is often a config change. That's a brutal position for the frontier labs: the differentiation is genuine, but it's perishable, and it resets every release cycle.
The memory layer is different. Right now it depends entirely on manual curation and stewardship. Humans writing, organizing, and pruning markdown. If someone figures out how to do this without the manual labor - e.g. a memory system that observes outcomes, learns what context predicts success for which task types, updates itself, and compounds in quality with use - that's an enormous value-add. And unlike the model, it would be genuinely hard to rip and replace. A sufficiently sophisticated proprietary memory system, trained on the accumulated specifics of your codebase and your team's outcomes, producing measurably better results, is exactly the kind of asset that creates switching costs. The model is a differentiated but swappable input; the memory is the moat.
The labs see this too, which is why the extension points keep multiplying. But the open question is whether the winning memory layer comes from a model vendor, an independent player, or the platform teams inside companies who build it themselves.
Where This Leaves Us
Real-world performance is the product of model and harness, and the people selling the models say as much themselves. Today's harnesses are curated markdown and good intentions, which is fine as a starting point and indefensible as an end state. The teams that will navigate the next few years well are the ones who develop rigor around their harness engineering practice: measuring task success rate, measuring spend per success, and treating every change, to the harness or the model, as an experiment with an observable result.
In 1996, the best way to find anything on the web was the Yahoo directory: humans reading websites, judging what was relevant, and filing it into a hand-curated hierarchy. It was the state of the art.
That's how markdown files in your agent coding harness feel today. Humans judging relevance, filing it into a hierarchy, pruning it by hand. State of the art, genuinely useful, and almost certainly a transitional artifact. We need the measurement apparatus that lets us know when it’s working, and when to replace it, because inevitably better techniques will show up.
(* = Harness engineering also includes the linters, test suite, and validation mechanisms that keep an agent on track, but let’s exclude those for now).